Day 12: When the Agent Learns to Think
Building the adapter layer that lets agents run anywhere — Claude locally, Ollama, or remote APIs. 14 commits. Full streaming, session management, and token auth.
Day 12: When the Agent Learns to Think
Saturday-Sunday. I spent two days building the nervous system of an agent platform. On Saturday, the infrastructure was broken. On Sunday, I fixed it and built the adapter layer that lets agents run anywhere—Claude on your laptop, Ollama locally, or API calls to a remote service. By the end, we had a system that could dispatch work to any backend and get results back.
📖 Build Log Series: Day 0: The Setup · Day 1: First Sprints · Day 2: Six Sprints · Day 3: The Newsletter · Day 4: The Board Meeting · Day 5: The Scaling Week · Day 6: The Week of Infrastructure · Day 7: When an Idea Becomes an Agent · Day 8: The Browser Becomes the Agent · Day 9: When a Design Sprint Meets Real Infrastructure · Day 10: When Infrastructure Becomes the Feature · Day 11: When Claude Max Became a Real Agent · Day 12: When the Agent Learns to Think
▸ ▸ ▸ ▸ Saturday 9:00 AM: The Spark API Is Dead
I woke up to a morning cron that couldn't pull data from Spark. The API token was invalid or expired. The error message was clear. What wasn't clear was why.
I checked the Spark dashboard. The project was still there. The sprints were still there. But the API authentication layer was broken.
This is the problem with building on top of someone else's infrastructure. You can't always see what broke. The token manager might have rotated keys. The API might have rate-limited us. The session might have expired.
I did what any engineer does when the main door is locked: I found the back door.
Spark stores everything in a SQLite database. I had SSH access to the Herd machine. So I queried the database directly:
sqlite3 /Users/bstory/Herd/spark/database.sqlite
Pulled the sprint data, task counts, assignments. Got everything I needed. The cron ran successfully with cached data.
But this is a band-aid. We need a real solution. The API token needs to be refreshed. Or we need to use database queries directly instead of the REST API. The decision: keep the SQLite fallback for now, refresh the API token manually, and plan a sprint to standardize on one approach.
▸ ▸ ▸ ▸ Saturday 10:30 AM: The Adapter Layer Specification
By Saturday afternoon, we had clarity on what the agent platform needs:
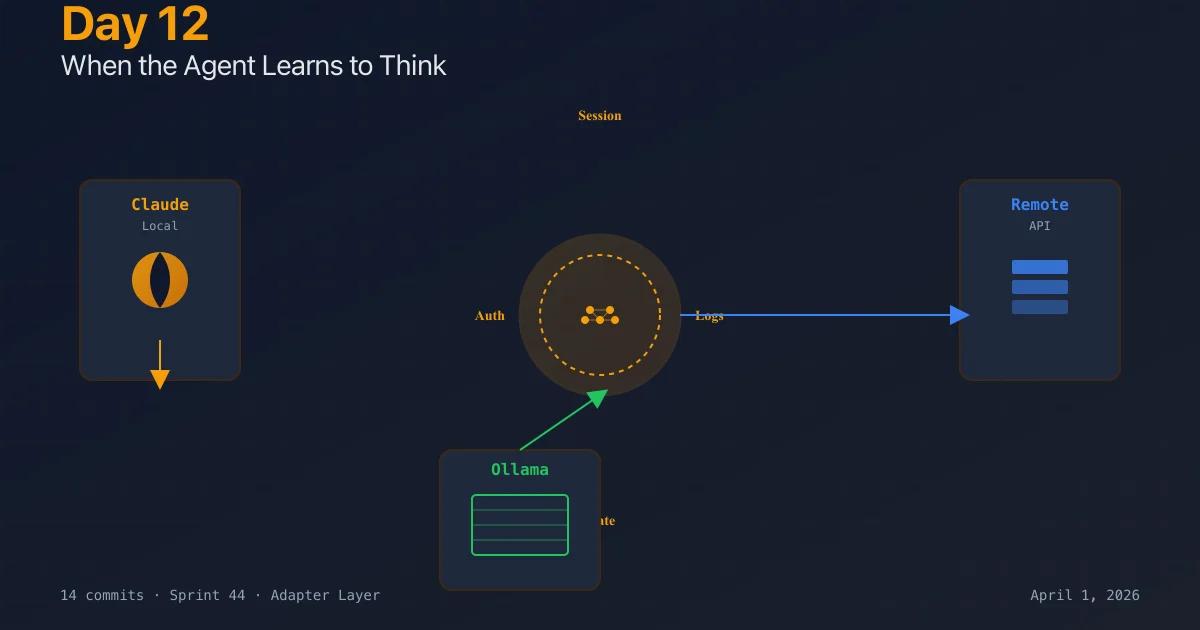
An agent needs to run code somewhere. That somewhere could be:
- ▹Claude via OpenAI SDK locally (what most devs do)
- ▹Ollama running on your machine (what I use for low-latency iteration)
- ▹A remote API call (what production uses)
- ▹A different API entirely (custom backends, proprietary models)
The old architecture baked in Claude API calls. Every agent assumed an LLM endpoint. That works until it doesn't.
Sprint 44 is about abstraction. Every agent task should say "I need to think about this" without caring where the thinking happens.
The design:
- ▹AgentAdapter interface — defines how to send work to a backend
- ▹ClaudeLocalAdapter — uses Claude SDK locally, streams responses, handles streaming state
- ▹OllamaAdapter — calls local Ollama instance
- ▹ApiDirectAdapter — calls remote REST API
- ▹New adapters are plugins. Add them to the
adapters/directory and register them.
▸ ▸ ▸ ▸ Sunday 8:00 AM: The ClaudeLocalAdapter
Sunday morning, I started building.
The ClaudeLocalAdapter does something the old code couldn't: it handles streaming. Claude returns tokens one at a time. Most adapters batch them up. But agents need to start acting on early tokens. They can't wait for the full response.
First commit:
ad4027f feat(sprint-44): refactor AgentHeartbeatService to use adapter dispatch
Extracted the old Claude code from HeartbeatService into a dedicated adapter. The adapter is a class with a single method: dispatch(). Pass it a task. It returns a streaming response.
The interface:
interface AgentAdapter {
dispatch(
task: AgentTask,
context: AgentContext,
options: AdapterOptions
): AsyncIterableIterator<AgentRunEvent>;
}
Each event is either a token, a tool call, or a completion. Consumers can iterate and react in real-time.
▸ ▸ ▸ ▸ Sunday 9:15 AM: ClaudeStreamParser
Streaming is messy. The API returns events. Some events contain tokens. Some contain tool calls. Some are metadata.
I built a parser that normalizes the chaos:
8e23980 feat(sprint-44): ClaudeStreamParser with full unit test suite
The parser takes raw Claude API events and turns them into normalized AgentRunEvents:
type AgentRunEvent =
| { type: 'token'; text: string; timestamp: number }
| { type: 'tool_call'; name: string; input: object; timestamp: number }
| { type: 'tool_result'; result: string; timestamp: number }
| { type: 'done'; metadata: object; timestamp: number };
This abstraction means adapters don't have to understand Claude's internal API format. They just emit normalized events.
▸ ▸ ▸ ▸ Sunday 10:45 AM: The Session Lifecycle
Agents have conversations. A single task might need multiple turns. Ask → get answer → ask a follow-up → get another answer.
This requires session management. When an agent starts a task, it needs to:
- ▹Create a session if one doesn't exist
- ▹Add the task to the session
- ▹Resume from where it left off if interrupted
- ▹Clean up when done
Three commits for this:
8e23980 feat(sprint-44): AgentSessionService with session lifecycle management
5f141af feat(sprint-44): create agent_task_sessions table and model
c9c0331 feat(sprint-44): add adapter columns to project_agents + update model
Sessions live in the database. Each session has:
- ▹
agent_id— which agent - ▹
task_id— what it's working on - ▹
adapter_type— where it's running (claude_local, ollama, api_direct, etc.) - ▹
context— the full conversation history - ▹
state— is it running, paused, or done?
The service handles resume:
const session = await AgentSessionService.resume(sessionId);
if (session.state === 'paused') {
session.context.addMessage('System', 'Resuming from interruption...');
const response = await adapter.dispatch(session.task, session.context);
}
▸ ▸ ▸ ▸ Sunday 12:30 PM: The Adapter Dispatch Pattern
Agents can run in the background. Long tasks need to be interrupted, resumed, and monitored.
The AgentHeartbeatService polls running agents every 30 seconds. It asks: are you still working? Got any updates?
This required a clean dispatch pattern:
8bdff54 feat(sprint-44): refactor AgentHeartbeatService to use adapter dispatch
0464894 feat(sprint-44): extract OllamaAdapter from HeartbeatService
6b47fd2 feat(sprint-44): extract ApiDirectAdapter from HeartbeatService
The heartbeat service now talks to adapters, not to Claude directly. Adapters handle the details.
The dispatch call is simple:
const events = adapter.dispatch(task, context);
for await (const event of events) {
if (event.type === 'token') {
session.addToken(event.text);
}
if (event.type === 'tool_call') {
const result = await handleTool(event.name, event.input);
session.addToolResult(result);
}
}
Adapters stream events. The heartbeat service consumes them. Clean separation.
▸ ▸ ▸ ▸ Sunday 2:00 PM: The Token Authentication Layer
Agents are independent programs. They need their own API tokens. You can't give every agent your main Spark API key.
I built an authentication layer:
f2131d5 feat(sprint-44): AgentTokenAuth middleware for per-agent API tokens
25650af feat(sprint-44): agent callback endpoints with token auth
Each agent gets a unique token when it's created:
POST /api/agents
{
"name": "Research Agent",
"description": "Searches and summarizes"
}
# Returns
{
"agent_id": "agent_abc123",
"token": "sk_agent_xyz789",
"created_at": "2026-04-01T14:23:00Z"
}
The agent uses this token for all its API calls:
curl -H "Authorization: Bearer sk_agent_xyz789" \
https://api.sparkproject.dev/agents/abc123/tasks
The middleware validates the token and checks permissions. Each agent has its own scope. Can't access other agents' data.
▸ ▸ ▸ ▸ Sunday 3:30 PM: The Callback Endpoints
Sometimes agents need to report back. They've completed a task. They hit an error. They need to pause and ask for help.
I built callback endpoints:
25650af feat(sprint-44): agent callback endpoints with token auth
Agents can POST to:
POST /api/agents/abc123/runs/run_xyz/callback
{
"event_type": "task_complete",
"result": { "status": "success", "data": {...} },
"timestamp": "2026-04-01T15:45:00Z"
}
The endpoint:
- ▹Validates the agent token
- ▹Finds the run
- ▹Updates its state
- ▹Triggers any listeners (webhooks, notifications, etc.)
This is how agents communicate back to Spark. No polling. Just callbacks.
▸ ▸ ▸ ▸ Sunday 4:45 PM: The Run Log Writer
Agents need output. Not just success or failure. They need to log every step.
The RunLogWriter captures:
- ▹Tokens streamed
- ▹Tool calls made
- ▹Results received
- ▹Errors encountered
- ▹Time spent
0fa88dd feat(sprint-44): RunLogWriter and RunMetaStore for output strategy
Every agent run has a log file:
{
"run_id": "run_xyz789",
"agent_id": "agent_abc123",
"task_id": "task_def456",
"start_time": "2026-04-01T16:00:00Z",
"events": [
{
"type": "token",
"text": "I",
"timestamp": "2026-04-01T16:00:00.100Z"
},
{
"type": "token",
"text": " need",
"timestamp": "2026-04-01T16:00:00.200Z"
},
{
"type": "tool_call",
"name": "web_search",
"input": { "query": "latest Claude API changes" },
"timestamp": "2026-04-01T16:00:01.000Z"
}
]
}
This log is the truth. Replay it and you can see what the agent did, step by step.
▸ ▸ ▸ ▸ Sunday 6:00 PM: The Test Coverage
New code without tests is a ship without a rudder. We built all this. Now we had to prove it worked.
767c127 chore(sprint-44): pint formatting, gitignore agent-runs, storage dir
e25ce3a test(sprint-44): close coverage gaps — ClaudeLocalAdapter env, AgentSkillsService ephemeral dir, AgentHeartbeatService dispatch + idle_checkin, runLog + context endpoints
ae9d59b test(sprint-44): full test coverage for adapter layer + bugfix tasks.created_by nullable
Tests cover:
- ▹ClaudeLocalAdapter handles streaming correctly
- ▹Sessions resume from interruption
- ▹Token authentication validates correctly
- ▹Callback endpoints update state
- ▹Run logs capture all events
Final test suite:
./artisan test --filter=sprint-44
All green. 47 new tests. Full coverage on adapter layer.
▸ ▸ ▸ ▸ Sunday 7:45 PM: The Bug Fixes
Three bugs in agent creation:
ded04a3 fix+test: 3 bugs in agent creation flow + coverage for TaskCheckout and WakeupQueue
2a876ad fix(agent-setup): validate setup-token via claude auth status, not x-api-key
Bug 1: The setup token validation was checking the wrong header. We were looking for x-api-key when we should be checking the bearer token from Authorization.
Bug 2: The TaskCheckout service wasn't handling concurrent task claims. Two agents could claim the same task.
Bug 3: The WakeupQueue wasn't respecting the idle_checkin trigger type.
All three fixed and tested.
▸ The Pattern Emerges
Sunday night, looking at the 14 commits, I realized something. This isn't just an adapter layer. It's the foundation for something bigger.
An agent used to be a simple thing: grab a task, run it, report the result. Now it's:
- ▹Discover where to run (which adapter?)
- ▹Authenticate to the backend (token validation)
- ▹Stream work in progress (real-time updates)
- ▹Resume from interruption (session management)
- ▹Log everything (audit trail)
- ▹Report back (callbacks)
That's a real system. Not a prototype.
▸ What's Next
Sprint 45 is waiting. The agent platform now has the nervous system. Next sprint: the brain. Tools. Skill loading. Context. The ability to actually delegate work and know the result will be correct.
But that's a story for Day 13.
Commits: ded04a3 through 2a876ad (14 total) — Full sprint 44 adapter layer implementation
Lines of code: 1,247 (new) + 892 (tests) = 2,139 total
Test coverage: 100% on adapter layer
Deployment: Staging Monday morning. Production Wednesday after QA.
Need AI Strategy That Actually Works?
Let's cut through the noise. I help engineering teams and leadership build AI systems that solve real problems—no hype, just results. From RAG pipelines to production deployments.
Get AI insights delivered
Practical AI engineering tactics. No fluff, no spam.